Linear Regression의 Hypothesis와 cost

Supervisored learning 한다고 가정
data를 가지고 진행
0~100 점 사이
regression
data를 가지고 학습
trainning
data 는 trainning data
regression medel이 data를 가지고 학습
학습이 끝난 후에
regression의 사용은
ex) 7시간 공부
AI에게 질문 이 학생이 몇점이나 받을 수 있을까?
기존 데이터를 이용해서 예측한다.
기본적인 ML의 컨셉
Linear regression

x,y는 서로의 관계를 나타내며 여기서는 학습데이터이다.

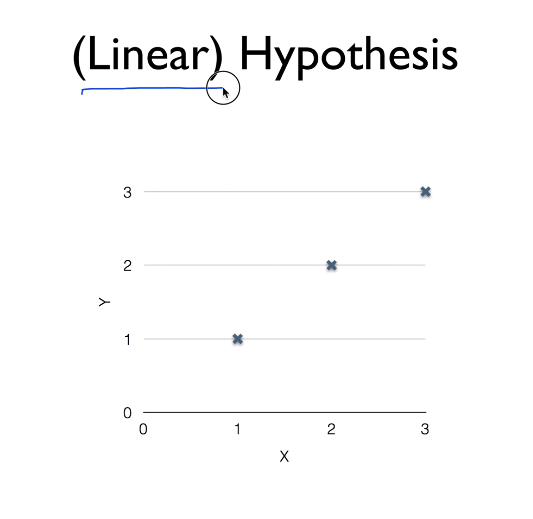
- Linear Hypothesis


어떤 데이터가 있다면 여기에 맞는 linear한 선을 찾는 것이라고 할 수 있다.
알맞는 선을 찾는게 학습이라 할 수 있다.
가설과 실제 데이터가 서로 가까울 수록 알맞은 선이다.
어떤 linear가 우리가 가진 데이터에 알맞은 linear일지 알아낼 수 있어야한다.
H(x) = Wx +b
가중치를 알아야한다.
- Cost function
가설과 실제 데이터의 차이를 알아낼 때 사용
How if the line to our (training) data

(H(x) -y)^2
음수가 있어도 제곱을 사용하므로 둘의 차이에 따른 가중치를 알 수 있으며
서로 간의 거리가 멀때
제곱이므로 값이 더 커진다.
그러므로 가설과 실제 데이터의 차이를 알아내는데 더 용이하다.


가설에서의 값과 실제 데이터의 값의 차이를 제곱한 것들의 평균 => Cost function

H(x) = Wx +b // 가설 linear 식
cost(W, b)의 값을 가장 적게 하는 것이 linear regression의 학습이 된다
가설과 실제 데이터의 차이를 적게하는 것이 목표이다.
trainning 시킨 모델이 나중에 실제 예측할 때 더욱 정확한 예측을 할수 있으므로 그렇다.

'AI > Deep Learning' 카테고리의 다른 글
| [모두를 위한 딥러닝(Sung Kim)|ch.1-2] TensorFlow의 설치 및 기본적인 operations (0) | 2020.12.27 |
|---|---|
| [모두를 위한 딥러닝(Sung Kim)|ch.1-1] Machine Learning의 용어와 개념 (2) | 2020.12.19 |

